
The majority of techies understand the difficulties of building a well-designed job queue inside a table of a relational database. But obviously for many this may not be the only choice or last choice. Usually, you create a job queue for SMS messages with the list of the messages in rows.
Although the job queue can be considered a good design pattern from the developer’s point of view but often it is challenging to implement in RDBMS because of multiple concurrent operations and the high amount of reading and write operation of any messaging app.
Further to this, you may also notice that amount of SMS traffic and any possible spike in traffic is highly unpredictable in the real-world scenario of messaging. And at times your queue can be really blocking and may behave differently. In a true sense, many of them aren’t really a problem in reality. But the potential is always there, and we have observed in the past that it’s hard to predict which thing will become a problem. This is usually because it depends on behavior that you don’t know in advance, such as which parts of your application will get the most load, or which customer of yours has suddenly decided to push a very large campaign.
Let’s go a little deeper as to why job queues can cause trouble for a high volume of traffic and may hamper the overall performance of any web application. Job queue works on the principle of polling. It means one or more worker processes are checking for something to do.
This starts to become a problem pretty quickly in a heavily loaded application and two major reasons are explained below:
Reason 1 Locking: Implementation of polling is usually run a SELECT FOR UPDATE to see if there are items to process; if so, UPDATE them in some way to mark them as in-process; then process them and mark them as complete. There are variations on this, not necessarily involving SELECT FOR UPDATE, but often something with similar effects. The problem with SELECT FOR UPDATE is that it usually creates a single synchronization point for all of the worker processes, and you see a lot of processes waiting for the locks to be released with COMMIT. Even a well thought the implementation of this can cause serious pile-ups of message traffic during any sudden spike.
Reason 2 Growth of Data: This symptom will appear when you have a sudden spike of traffic and a big fat table makes all the queries really, really slow. If you combine this with polling and/or locking and lots of load on the server, you have a recipe for epic disaster.
Now the real question is can we really manage our queues even during such spikes?
The answer is YES.
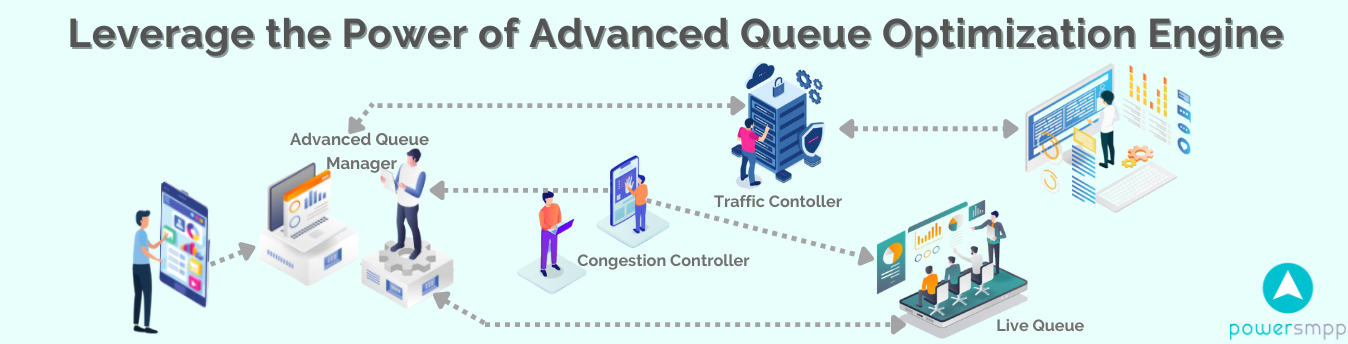
So, it’s not the implementation, technology, or resource, the biggest challenge is architecture. It may be noted that during a sudden spike of traffic, we actually do not increase our upstream dynamically but still, we expect our queue to perform with the same level of performance.
With the years of research and analysis on various heavily loaded real-time queues, we could figure out that the right architecture is the only way for a messaging app to handle unpredictable traffic flow. While thinking on this line, it was also challenging for us to develop something unique which is compatible with the existing system.
Finally, we have arrived at a solution of implementing an add-on plugin called “Advance Queuing System” to pre-process the message queue with an additional proprietary queuing algorithm which will perform intelligent load balancing and inject the message data into the primary queue based on various system parameter, such as available system resource, current backlog, in-queue messages, upstream bandwidth, etc. Such implementations are very effective in many ways to handle the performance issues in Web apps.
Such implementations also give you predictability over your resources. Since the resources used are determined by the “Advanced Queuing System” that read from the intermediary queues this will always be a reliable solution, even if you have a spike in traffic and the system will not go down. The only overhead will be that the messages will just take a longer time to process if you do not have enough upstream bandwidth.
Our Previous Posts:
Convert SMS HTTP API into SMPP API in your Software in less than 3 minutes