
This article written based on our experience in the real-world in messaging domain. Though the writing may not be very impressive, we can assure you that a complete reading will give you enough information on how to scale with speed.
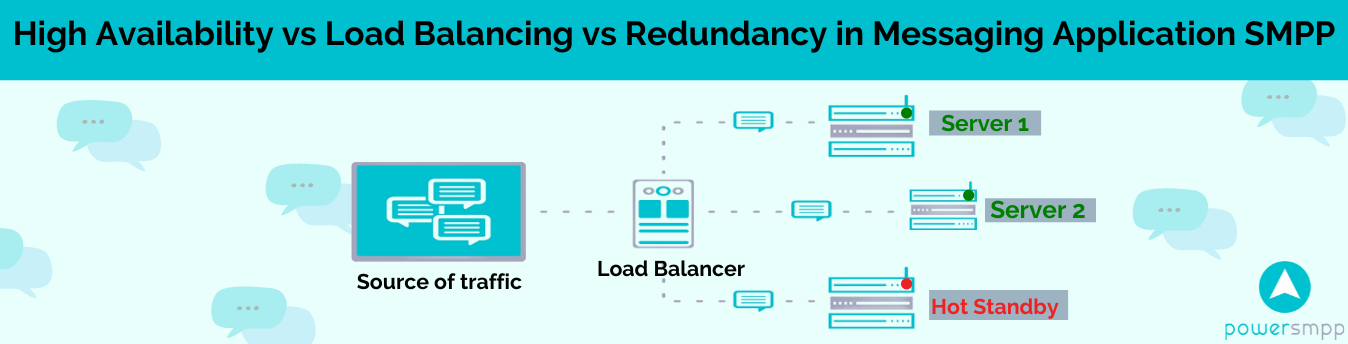
I often get requests from our clients for the high availability of their application. While requesting high availability most of the time people assume that it will also act as a load balancer and scale their application. But it is not true. The load balancer is actually a prerequisite to implementing high availability.
Before I discuss further on the load balancer, let me briefly tell you that high availability precisely means running your application from multiple geo-location which can be within a country or can be in two different continents. Choosing the ideal scenario depends on your customer base. If you are catering to only a domestic audience then it’s better to host your services within the same country to avoid any undue latency.
Coming to redundancy, the scope is very wide. The degree of redundancy is relative and varies from man to man. An organization may feel that having their application running from two different geo-location is redundant, whereas at the same time another organization may like to put some more servers on different continents to make their application even more redundant for global audiences. Some may be happy with a single load balancer whereas, at the same time, some may think of adding multiple load balancers to achieve a near-zero downtime. In short, redundancy is a relative choice and should be decided based on criticality and affordability.
The load balancer is usually configured to distribute traffic based on a round-robin algorithm to all the healthy and connected nodes. It also does a health check at regular intervals to keep a track of healthy nodes. For pure TCP traffic such as SMPP, you need a TCP-based load balancer and for web servers, you can use Nginx as the load balancer.
Challenges –
The biggest challenge of setting up a high availability application is regular updates. Any new update needs to be pushed to all the locations. If you are using a docker container, there are tools available to make your life easier. RESTful API updates are straightforward, but in the case of large web applications, it is highly recommended to use CDN for all the assets, to make the updates smoother.
Now that your application is fully redundant, it’s time to discuss other components such as caching Db, SQL databases, any other service running important job, file system (logs), upstream connectivity, etc. Can we make everything redundant? The answer is yes with some riders. Let’s go one by one.
Database –
Enough work has been done by the Open source community to make major databases highly scalable. For SQL databases, sharding(horizontal scaling) should be treated as a buzzword and should be adopted as a last resort especially when you have exhausted all the options to increase your write.
Note – A quick suggestion is to use SSD drives to increase your write performance.
The moment you decide to scale horizontally, it’s day zero for you and the entire application may require an architectural change. So my humble suggestion is to scale horizontally as long as possible.
Humble suggestions on designing Database Architecture :
One: Never limit yourself to running a single instance to save some cost. From day one, you must opt for a replication server sitting at a different geo-location. At the initial stage, we try to keep the application and DB on the same machine to save some cost. But, what happens if you are attacked with ransomware when you are just getting started? Your replication server will come to your rescue. There will be some downtime, but it will save you from going into depression. So the thumb rule is to use a replication server from day one of your business.
Important Note: RAID and replication are not the same. RAID can safeguard you from physical damage to disk but not from ransomware.
Two: Try to keep your DB server on a different machine for better performance and added security.
Three: When you reach the write bottleneck (IOPS), try to use one of your replication machines as a reading node. Even if it fails to handle the desired load of traffic, do not waste your time adding a new machine to your cluster. If you have more than two machines and make one of them a proxy. (Details on setting up of Proxy are out of the scope of this blog, but it’s not that complicated if you know how to do it.
Final Say:
Scaling your DB is a decision rather than know-how. Go for vertical scaling followed by cluster. Sharding should be avoided.